circleci tests split --split-by=timingsについて調べた・自作してみた
この記事はCircleCI Advent Calendar 2018の24日目の記事です。
テスト分割実行ファンの皆さんこんにちは。
今回はCircleCIの並列テストにおいて、いい感じにテストファイルを分割することを考えていきたいと思います。
【イメージ アニgif】

テストファイルをいい感じに分割したい
まず前提として、「いい感じに分割したい」とはどういうことかということを説明します。
例えば今、テストファイルが7個あって、それぞれのテストにかかる時間が経験上「10秒、6秒、5秒、4秒、3秒、2秒かかる」ということがわかっているとします。
この場合、普通に1プロセスで実行すると10+6+5+4+3+2で30秒かかります。

ここで、CircleCIでparallelism: 3(3並列)で分割テストすることを考えます。
まず悪い例として「[10, 3], [6, 5], [4, 2]」と分割してみます。そうすると以下のようになり、一番遅いやつが13秒(10+3)なので全体として13秒かかることになります。
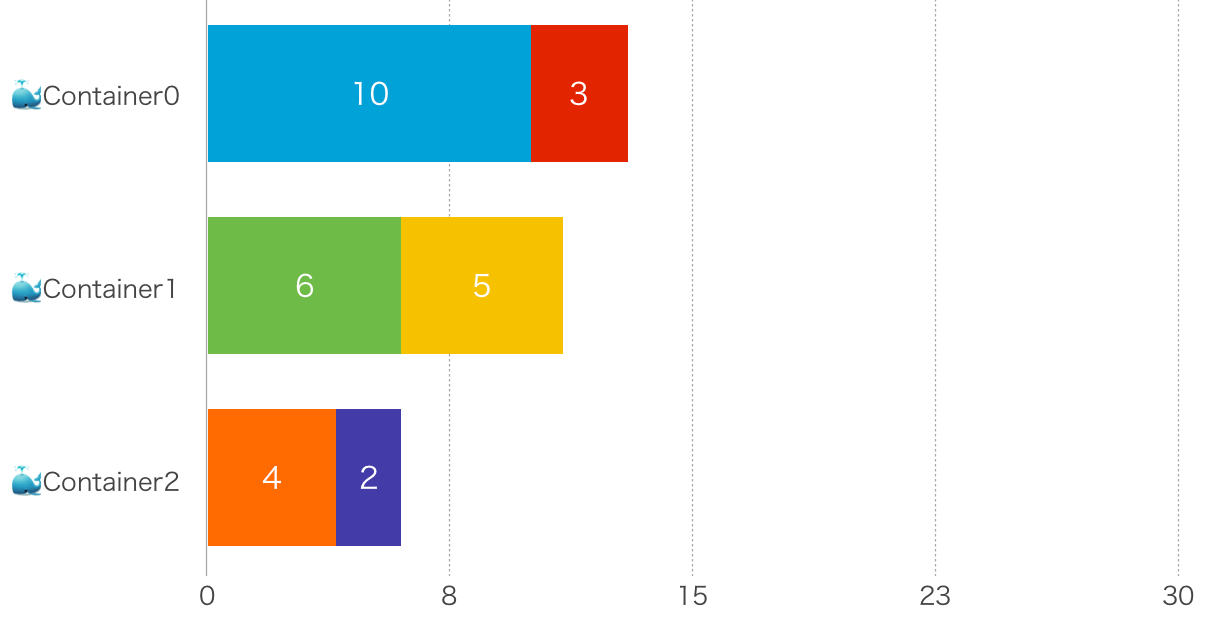
次に、それよりは少しましな例として「[10], [6, 3, 2], [5, 4]」と分割します。すると以下のようになり、一番遅いやつが11秒(6+3+2)ということになります。
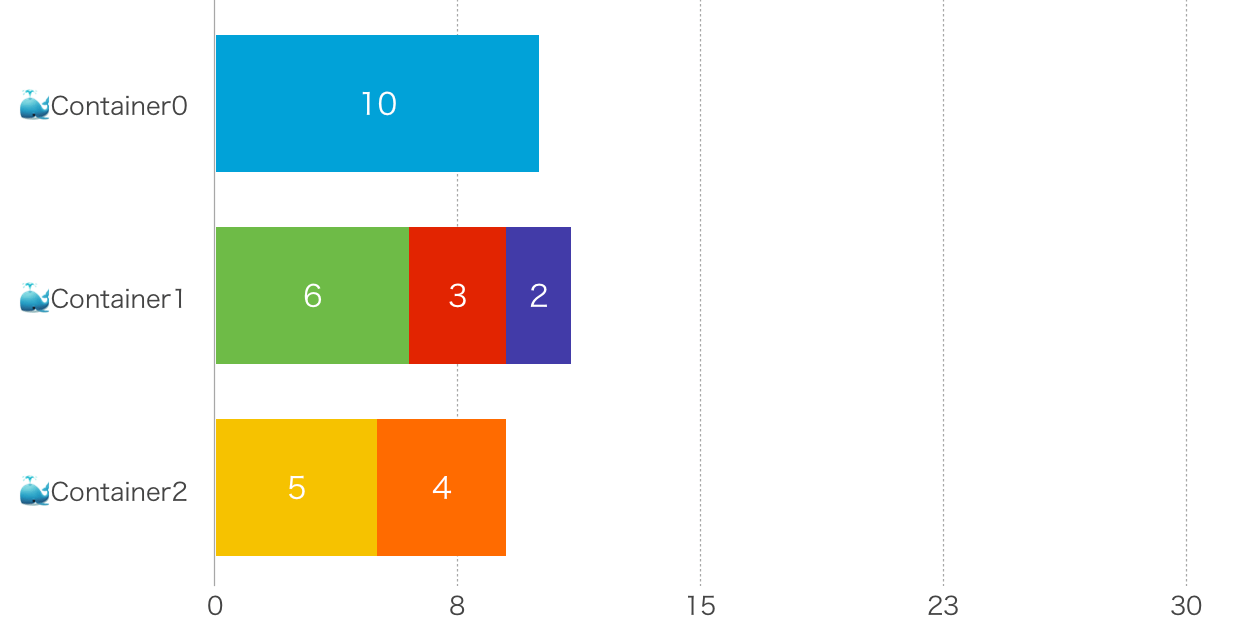
つまり、分割の仕方によって全体のテスト時間が変わってしまう!(13秒 vs 11秒) ということになります。
ということで、全体のテスト時間を短くするためには、いい感じに分割するアルゴリズムが求められるということになります。
このファイル分割は、整数計画問題(wikipedia) とか ナップサック問題(wikipedia)のような問題のたぐいです。
circleci tests split –split-by=timings
これをうまくやってくれるのが circleci tests split --split-by=timings です。
rspecの場合、以下のように使います。(CircleCI公式の説明から引用)
$ TESTFILES=$(circleci tests glob "spec/**/*.rb" | circleci tests split --split-by=timings)
$ bundle exec rspec -- ${TESTFILES}
前半のcircleci tests glob "spec/**/*.rb" は、テスト対象のファイルのリストを改行区切りで出力します。
$ circleci tests glob "spec/**/*.rb"
spec/foo_10_spec.rb
spec/foo_2_spec.rb
spec/foo_3_spec.rb
spec/foo_4_spec.rb
spec/foo_5_spec.rb
spec/foo_6_spec.rb
次のcircleci tests split --split-by=timings は、それを標準入力で受け取り、分割結果を返します。
これはコンテナ毎に結果が異なります。
# コンテナ0では
$ circleci tests glob "spec/**/*.rb" | circleci tests split --split-by=timings
spec/foo_10_spec.rb
# コンテナ1では
$ circleci tests glob "spec/**/*.rb" | circleci tests split --split-by=timings
spec/foo_6_spec.rb
spec/foo_3_spec.rb
spec/foo_2_spec.rb
# コンテナ2では
$ circleci tests glob "spec/**/*.rb" | circleci tests split --split-by=timings
spec/foo_5_spec.rb
spec/foo_4_spec.rb
それを rspecの引数に渡すことにより、container毎にうまく分割されるようにしているのです。
circleci tests split –split-by=timings が動くために必要なこと
ここから先はドキュメントを読んだり自分で試したりして調べた内容です。
(なお –split-by=filesizeとか –timings-type=classnameについては調べてません! あしからず)
「環境変数」と「タイミングデータ」が必要になります。
環境変数
これらは自動的に設定されるので普通は意識する必要はありません。
以下の環境変数が利用されます。
CIRCLE_NODE_INDEX- コンテナの番号。0オリジン。これを利用することによりコンテナ毎に別のテストファイルを実行することができる。
CIRCLE_NODE_TOTAL- 全体の並列実行数。
parallelism:で設定した値。
- 全体の並列実行数。
CIRCLE_INTERNAL_TASK_DATA- タイミングデータ(過去のspec実行時間)が保存されるディレクトリ。
タイミングデータ
タイミングデータを利用するには、Test Metadataと呼ばれるXMLファイルをCircleCIに教えてあげる必要があります。
rspecの場合、rspec_junit_formatter gem とか使うアレです。
Collecting Test Metadata - CircleCIを参考してください。
これが設定されていれば、パス ${CIRCLE_INTERNAL_TASK_DATA}/circle-test-results/results.json にタイミングデータ(過去のspec実行時間)が保存されているはずです。
そのresults.jsonの中身は、およそ以下のようになっています(本当はもっと複雑ですが必要なノードだけ記載しています)。
expectationごとにテストにかかる時間の秒数が載っています。
{
"tests": [
{
"file": "spec/foo_10_spec.rb",
"run_time": 10.0
},
{
"file": "spec/foo_6_spec.rb",
"run_time": 6.0
},
...
],
}
このjsonのフォーマットについては、ドキュメントに書かれていなかったので、今後変わるかもしれません。
ちなみに、初回テスト実行時には、タイミングデータは無いので、--split-by=timingsを使っても、Requested historical based timing, but they are not present. Falling back to name based sorting というメッセージが表示され、ファイル名でのソートになります。
circleci tests split –split-by=timings のアルゴリズム検証
簡単な実験を行います。
のような状態を再現するため、
タイミングデータresults.jsonを以下のような中身にします。
{
"tests": [
{
"file": "spec/foo_10_spec.rb",
"run_time": 10.0
},
{
"file": "spec/foo_6_spec.rb",
"run_time": 6.0
},
{
"file": "spec/foo_5_spec.rb",
"run_time": 5.0
},
{
"file": "spec/foo_4_spec.rb",
"run_time": 4.0
},
{
"file": "spec/foo_3_spec.rb",
"run_time": 3.0
},
{
"file": "spec/foo_2_spec.rb",
"run_time": 2.0
}
]
}
.circleci/config.ymlを以下のようにします。
実験のために
CIRCLE_NODE_TOTAL,CIRCLE_NODE_INDEX,CIRCLE_INTERNAL_TASK_DATAを上書きしているのがポイントです。
version: 2.1
jobs:
build:
docker:
- image: circleci/ruby:2.5.3
environment:
CIRCLE_NODE_TOTAL: "3"
CIRCLE_INTERNAL_TASK_DATA: "."
steps:
- checkout
- run:
name: CIRCLE_NODE_INDEX=0 circleci tests split --split-by=timings
command: circleci tests glob "spec/**/*_spec.rb" | CIRCLE_NODE_INDEX=0 circleci tests split --split-by=timings
- run:
name: CIRCLE_NODE_INDEX=1 circleci tests split --split-by=timings
command: circleci tests glob "spec/**/*_spec.rb" | CIRCLE_NODE_INDEX=1 circleci tests split --split-by=timings
- run:
name: CIRCLE_NODE_INDEX=2 circleci tests split --split-by=timings
command: circleci tests glob "spec/**/*_spec.rb" | CIRCLE_NODE_INDEX=2 circleci tests split --split-by=timings
この実験のソースコードはこちらに置きました。
https://github.com/hoshinotsuyoshi/circleci-tests-split-split-by-timings/tree/study1
すると、結果は以下のようになりました。
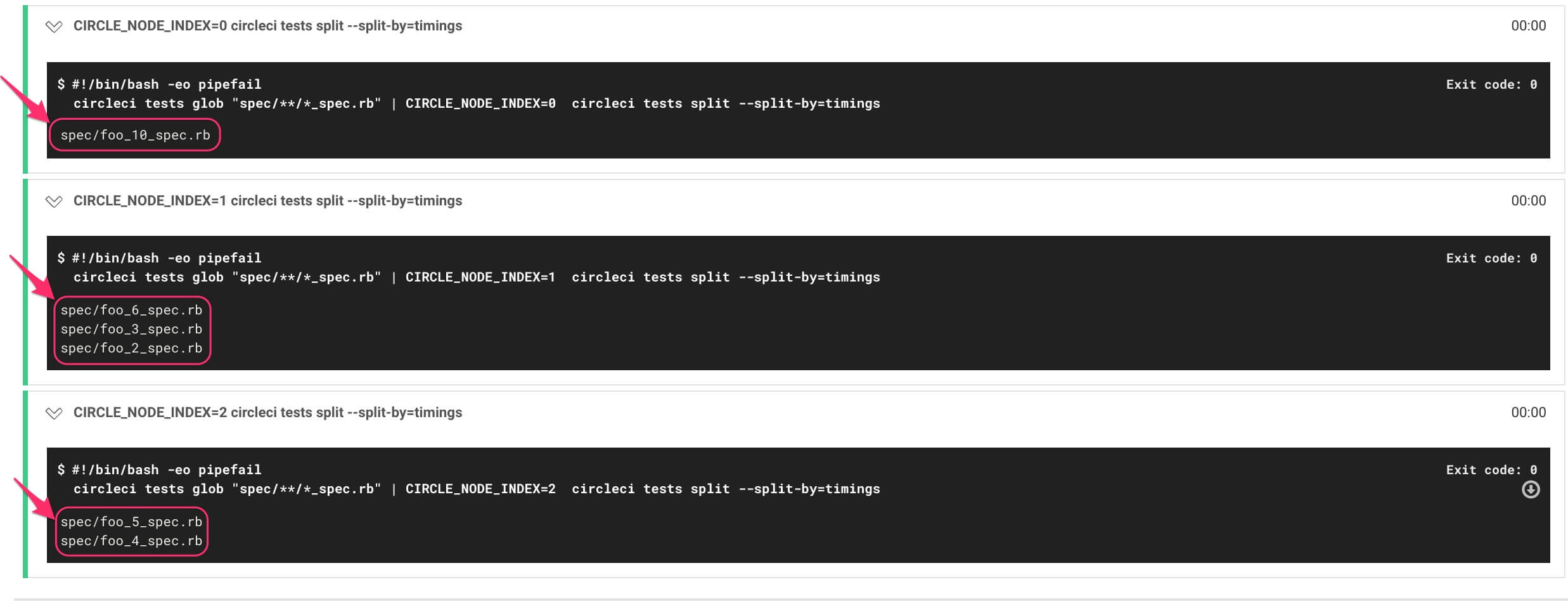
つまりcircleciは、この6個のテストファイルを[10], [6, 3, 2], [5, 4]というに分割しました。(以下のような感じ)
本当の最適解
実はこの与件の場合、[10], [6, 4], [5, 3, 2] というふうに分割するのが最適解(10秒)です。
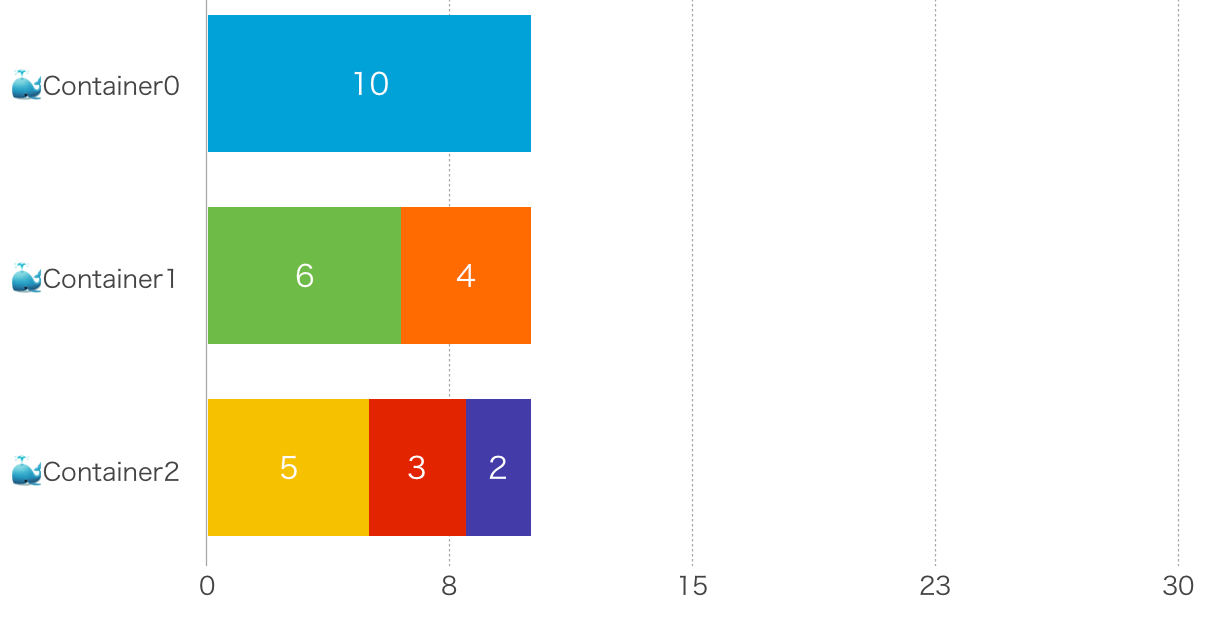
circleciは、なぜ最適解を求めてくれなかったのでしょうか?
貪欲法っぽい?
何度かパターンを変えて実行してみたのですが、
おそらくcircleci tests split –split-by=timings は以下のような戦略で分割しているものと思われます。
- 実行時間の長い順に処理する
- 最もトータルの実行時間が短い入れ物に入れていく
アニメにするとこんな感じです。
これは、アルゴリズムとしては貪欲法(wikipedia)と言われるやつだと思います。
最適解を出そうとすると、ファイル数が多い場合に組み合わせパターンが増えてしまうため(動的計画法を使ってもそこそこ増える)、このようなシンプルなアルゴリズムを利用しているのだと思います。
最適解じゃなくても、これで十分ぽい
もっと現実的なrailsアプリに近いタイミングデータで検証してみました。
具体的には職場のrailsアプリのデータを拝借してsplitしました。
3分割すると結果は
- container 0 … 150.0602秒
- container 1 … 150.0613秒
- container 2 … 150.0606秒
というふうになり、コンテナ間のテスト時間の理論的なギャップが0.1秒以内に収まりました。
実行時間の小さいspecファイルが多いようなrailsアプリの場合、貪欲法でも十分に効率的なsplitができるのだと思われます。
splitスクリプトを自作してみる!!
環境変数とタイミングデータの場所がわかったので、同じような処理をするスクリプトを自作することができます。
同じようなアルゴリズムのスクリプトをrubyで実装してみました。
実験に使ったソースはこちら。
https://github.com/hoshinotsuyoshi/circleci-tests-split-split-by-timings/tree/custom_script
#!/usr/bin/env ruby
# frozen_string_literal: true
# circleci-tests-split-split-by-timings
require 'json'
require 'pathname'
INDEX = ENV.fetch('CIRCLE_NODE_INDEX') { abort '$CIRCLE_NODE_INDEX is not set' }.to_i
TOTAL = ENV.fetch('CIRCLE_NODE_TOTAL') { abort '$CIRCLE_NODE_TOTAL is not set' }.to_i
# タイミングデータのパース
def timing_data
dir = ENV.fetch('CIRCLE_INTERNAL_TASK_DATA') { abort '$CIRCLE_INTERNAL_TASK_DATA is not set' }
json = Pathname(dir) + 'circle-test-results/results.json'
json.exist? || abort("#{json} does not exist")
tests = JSON.parse(json.read)['tests']
# [
# {
# "file" => "spec/1_spec.rb",
# "run_time" => 1.0
# },
# {
# "file" => "spec/2_spec.rb",
# "run_time" => 2.0
# },
# {
# "file" => "spec/1_spec.rb",
# "run_time" => 2.5
# },
# ...
# ]
hash = Hash.new(0)
tests.each do |t|
hash[t['file']] += t['run_time']
end
hash
# {
# "spec/1_spec.rb" => 3.5,
# "spec/2_spec.rb" => 2.0,
# ...
# }
end
# 標準入力(テスト対象ファイルリスト)を配列に入れる
file_names = []
while file_name = gets&.chomp
file_names << file_name
end
# テスト対象ファイルを実行時間が長い順にソート
sorted =
timing_data
.slice(*file_names)
.sort_by { |_file, run_time| run_time }
.reverse
.to_h
# タイミングデータにデータは無いファイルの処置
missings = (file_names - sorted.keys)
missings.each do |file_name|
sorted[file_name] = 0
end
# 貪欲法
# コンテナの数だけ入れ物を作り実行時間が長い順にファイルを詰めていく
# トータルの実行時間が一番小さい入れ物にファイルを詰める
pods = Array.new(TOTAL) { { content: [], total: 0 } }
sorted.each do |file, run_time|
smallest = pods.min_by { |pod| pod[:total] }
smallest[:content] << file
smallest[:total] += run_time
end
# 自コンテナが担当すべきファイルリストを出力
puts pods[INDEX][:content]
実際に実行したところ、circleciコマンドの結果と同じようなsplit結果となりました♬
本当なら動的計画法+golangでいい感じのスクリプト書きたかったんだが、、時間(及びスキル)がなかったんや…
まとめ
まとめます。
- circleci tests split –split-by=timings は貪欲法を活用してると見られ、最適解が求まらないが、十分効率的
- 少なくとも普通のrails+rspecなら十分ぽい
- circleci tests split –split-by=timings のようなものは自作可能
- タイミングデータをパースして環境変数を読み込めば、オレオレsplitスクリプトを作成できる
- 最適解も夢ではない
あまり得意でない分野について書いたので、間違いがあったら教えてください :pray:
